






























Introduction
The Transformer architecture has revolutionized the field of deep learning, particularly in natural language processing (NLP), computer vision, and other domains of artificial intelligence. Introduced by Vaswani et al. in 2017, the Transformer model has quickly become the foundational building block for state-of-the-art models, such as BERT, GPT, T5, and many more. By eliminating the limitations of previous architectures, such as recurrent neural networks (RNNs) and long short-term memory (LSTM) networks, Transformers have enabled significant advancements in various AI fields. This article explores the key components of the Transformer architecture, its impact on deep learning, and its applications across multiple domains.
The Rise of the Transformer Architecture
Before the introduction of the Transformer, sequence-to-sequence models, which were based on RNNs and LSTMs, dominated the field of NLP. These architectures worked by processing sequences of data step-by-step, maintaining a hidden state to encode information as the sequence progressed. While effective, these models struggled with long-range dependencies due to their sequential nature. In other words, they had difficulty retaining context from earlier parts of a sequence when generating later parts, which is particularly challenging in tasks like machine translation or long text summarization.
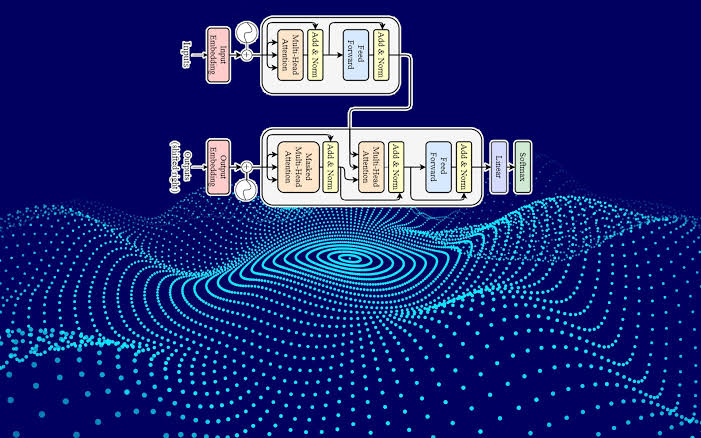
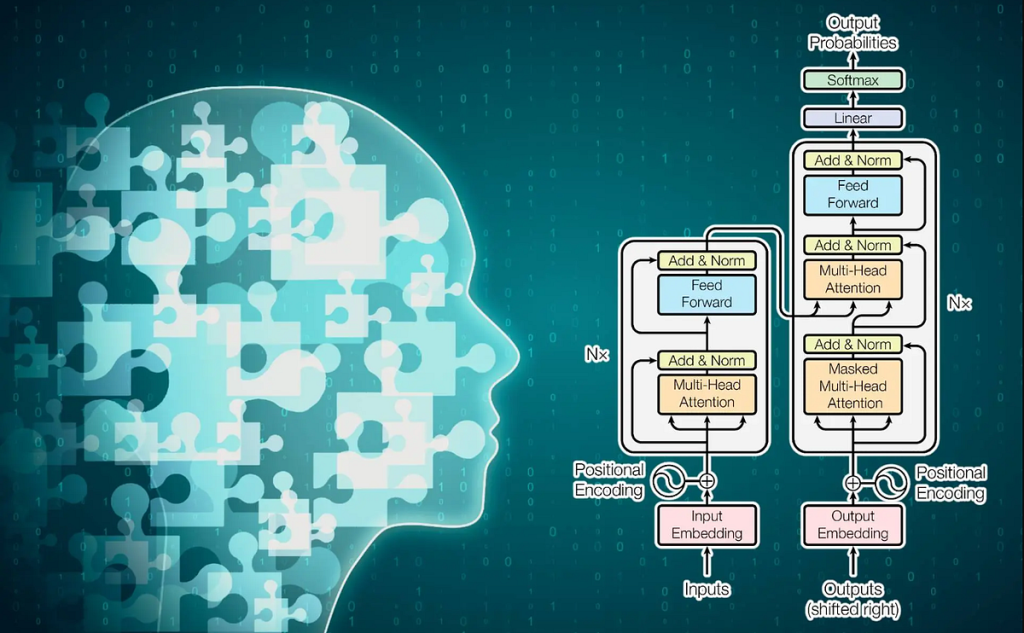
In 2017, the paper “Attention is All You Need” by Vaswani et al. introduced the Transformer model, which abandoned the sequential processing of RNNs in favor of a parallelized, attention-based mechanism. This allowed the Transformer to process sequences more efficiently and capture long-range dependencies more effectively. The architecture was designed with two main parts: an encoder and a decoder, each composed of multiple layers that work in tandem to process input data and generate predictions.
Key Components of the Transformer Architecture
- Self-Attention Mechanism
The self-attention mechanism is the core innovation of the Transformer model. In simple terms, attention allows the model to focus on different parts of the input sequence when producing each output. This contrasts with RNNs and LSTMs, which process input data sequentially. In the Transformer, each token (word or subword) in the input sequence can attend to every other token, regardless of its position, making it capable of understanding long-range dependencies much better.
The self-attention mechanism is mathematically represented by three vectors: queries (Q), keys (K), and values (V). The attention score for each token pair is computed by taking the dot product of the query and key vectors, followed by a softmax operation to normalize the scores. The output is a weighted sum of the value vectors, where the weights are determined by the attention scores.
This attention mechanism allows the Transformer to model relationships between all tokens in parallel, which significantly improves efficiency compared to RNN-based models. - Positional Encoding
Since the Transformer does not inherently process data in a sequential manner, it requires a method to encode the relative position of tokens in the sequence. This is where positional encoding comes in. Positional encoding is a technique that adds unique vector representations to each token based on its position in the sequence. These vectors are added to the input embeddings before being passed through the self-attention mechanism.
In the original Transformer paper, positional encoding is generated using sine and cosine functions with different frequencies. This method allows the model to easily distinguish between different positions while still being able to generalize across sequences of different lengths. - Multi-Head Attention
One of the key advantages of the self-attention mechanism is that it can focus on different aspects of the sequence simultaneously. Multi-head attention extends the idea of self-attention by allowing the model to learn multiple attention patterns in parallel. Rather than using a single attention mechanism, the Transformer uses several independent attention heads, each with its own set of learnable parameters. The outputs from these attention heads are then concatenated and linearly transformed to produce the final attention output.
Multi-head attention enables the Transformer to capture various dependencies at different levels of granularity, which enhances its ability to understand complex relationships in the data. - Feedforward Neural Networks
After the multi-head attention mechanism, the output is passed through a feedforward neural network (FFN). Each layer of the Transformer consists of two sub-layers: a multi-head self-attention layer and a position-wise feedforward network. The FFN consists of two fully connected layers with a ReLU activation function in between. This helps the model learn non-linear transformations and introduces additional capacity for learning complex patterns.
The FFN is applied independently to each position in the sequence, allowing the Transformer to maintain parallelism across the entire sequence. - Layer Normalization and Residual Connections
To stabilize training and improve convergence, the Transformer architecture uses layer normalization and residual connections. Residual connections are shortcuts that bypass one or more layers in the network, allowing the model to directly pass information from earlier layers to later ones. This helps mitigate the vanishing gradient problem and ensures that gradients can flow more effectively through the network during backpropagation.
Layer normalization is applied to the input of each sub-layer (such as self-attention and feedforward networks) to normalize the activations, reducing internal covariate shift and accelerating training. - Encoder-Decoder Structure
The Transformer is built around an encoder-decoder structure, which is essential for sequence-to-sequence tasks like machine translation. The encoder takes an input sequence and generates a sequence of encoded representations that capture the relevant information about the input. The decoder then uses these encoded representations to generate the output sequence, attending to both the encoded input and previously generated tokens.
Each encoder and decoder consists of multiple layers of self-attention and feedforward networks. The encoder’s layers focus on processing the input sequence, while the decoder layers incorporate both self-attention and encoder-decoder attention to generate the output sequence.
Impact of the Transformer on Deep Learning
The Transformer model has had a profound impact on the field of deep learning, especially in natural language processing. Prior to the Transformer, models like RNNs, LSTMs, and GRUs were the go-to architectures for sequential tasks. However, these models suffered from significant limitations, especially in terms of parallelization and long-range dependency modeling.
- Parallelization and Efficiency
One of the most significant advantages of the Transformer is its ability to process sequences in parallel. Since the self-attention mechanism allows for the simultaneous processing of all tokens in the sequence, the Transformer is much faster to train compared to RNN-based models, which must process data one token at a time. This parallelization enables the Transformer to take full advantage of modern hardware, such as GPUs and TPUs, resulting in faster training times and the ability to handle larger datasets. - Scalability
The Transformer architecture is highly scalable. Its parallel nature allows it to be trained on large datasets, making it ideal for tasks involving large-scale text corpora, such as language modeling and machine translation. The success of models like BERT and GPT, which are built on the Transformer, highlights the power of this architecture when applied to massive datasets. - State-of-the-Art Results
The Transformer has consistently outperformed previous models on a wide range of benchmarks. For instance, BERT (Bidirectional Encoder Representations from Transformers) revolutionized NLP by pre-training on large corpora and fine-tuning for specific tasks, achieving state-of-the-art results in tasks like question answering, sentiment analysis, and named entity recognition. Similarly, GPT (Generative Pretrained Transformer) has set new standards for language generation, achieving human-like text generation across various domains. - Transfer Learning
The introduction of transfer learning through the Transformer-based models has had a huge impact on the NLP community. Models like BERT, GPT-3, and T5 are pre-trained on massive corpora and can be fine-tuned on specific downstream tasks with relatively small datasets. This transfer learning approach has significantly reduced the need for task-specific models and allowed for more efficient deployment of deep learning systems.
Applications of the Transformer Architecture
- Natural Language Processing
The Transformer architecture has become the cornerstone of most modern NLP tasks. Some notable applications include:- Machine Translation: Models like Transformer and BERT have achieved state-of-the-art results in machine translation tasks.
- Text Generation: GPT-3, the largest Transformer-based language model, can generate coherent and contextually relevant text, making it useful for applications such as content generation, code completion, and creative writing.
- Text Classification: Transformers are used in various classification tasks, such as sentiment analysis and spam detection.
- Named Entity Recognition (NER): Models like BERT are highly effective in extracting entities such as names, dates, and locations from unstructured text.
- Computer Vision
Recently, Transformer-based models like Vision Transformer (ViT) have been applied to computer vision tasks, such as image classification and object detection. ViT replaces traditional convolutional neural networks (CNNs) with a Transformer that processes image patches as sequences, achieving competitive results on benchmark datasets like ImageNet. Transformers are also used in hybrid models that combine CNNs for feature extraction and Transformers for long-range dependencies and global context. - Speech Recognition
Transformers have also been applied in speech recognition tasks, replacing recurrent architectures for improved efficiency and accuracy. Models like Conformer combine the strengths of both convolutional and Transformer architectures to capture both local and long-range dependencies in speech data. - Healthcare
In healthcare, Transformer models are being applied to tasks like medical image analysis, genomics, and clinical data analysis. For instance, Transformers can be used to analyze radiology images, detect anomalies, and assist in early disease diagnosis.
Challenges and Future Directions
Despite the Transformer’s successes, several challenges remain:
- Memory and Computational Cost: The attention mechanism in Transformers scales quadratically with the input sequence length, making it expensive in terms of memory and computation for very long sequences.
- Model Interpretability: Transformer-based models, especially large-scale ones like GPT-3, are often criticized for being black boxes. Understanding how these models arrive at decisions remains a challenging task.
- Ethical Concerns: The massive scale of Transformer models raises concerns about their environmental impact due to the substantial computational resources required for training, as well as ethical issues surrounding the potential for misuse.
Nevertheless, the future of the Transformer is bright, with ongoing research focused on optimizing its efficiency, improving interpretability, and exploring its applications across new domains.
Conclusion
The Transformer architecture has fundamentally transformed the landscape of deep learning, driving progress in fields like natural language processing, computer vision, and speech recognition. Its parallel processing capabilities, scalability, and ability to model long-range dependencies have made it the go-to architecture for many state-of-the-art AI models. As research continues to evolve, we can expect even more powerful and efficient Transformer-based models to emerge, shaping the future of artificial intelligence.













{kind=link}